Renting AI GPUs for your ML projects can be expensive, and the pricing from major cloud providers can make even simple fine-tuning jobs feel like a luxury.
Developers regularly get priced out of experimenting with larger models, which is exactly why the AI GPU rental market is shifting so dramatically right now.
Breakdown
- The AI GPU rental market is projected to grow from $3.34B in 2023 to $33.91B by 2032, driving down costs.
- Tracked pricing ranges from $1.09-$5.07/hr for A100 80GB GPUs and $2.01-$11.06/hr for H100 80GB GPUs.
- Thunder Compute offers some of the lowest stable on-demand rates, with savings of up to 81% versus higher-priced competitors.
- Supply chain improvements eliminated shortages for a while, but recent demand spikes have decreased availability.
- Market is stabilizing around developer experience and reliability over pure price competition.
Projected Market Growth in AI GPU Rental
Data centers play a central role in the rise of AI, which puts them at the technological forefront. Demand is higher than ever. The global data center GPU market is projected to grow from $138.88 billion in 2026 to $624.17 billion by 2034.
The GPU rental market is not lagging behind, growing from $3.34 billion in 2023 to a projected $26.09 billion by 2032. These estimates appear well founded, since the market already reached $7.38 billion in 2026 and is expected to grow another 28.73% in 2027.
This explosive growth creates opportunities for developers, researchers, and startups who couldn't afford enterprise-grade GPUs. The GPU marketplace shows how renting has leveled the playing field.
LLM development, computer vision applications, and the growth of multimodal AI systems that require serious computational horsepower are driving this surge. Every startup looking to fine-tune their own models needs access to data center GPUs.
This growth benefits users by lowering prices and increasing reliability through competitive pressure. The current competitive market is forcing new developments in orchestration, performance, and user experience.
This market expansion has allowed Thunder Compute to offer affordable GPU cloud access at price points that would've been impossible two years ago.
Current GPU Pricing Trends - June 2026
H100 rental prices have seen some of the most dramatic shifts, leaving behind historical peaks near $8/hr to a much broader market range today. Across tracked providers, H100 80GB pricing now runs from $2.01/hr to $11.06/hr.
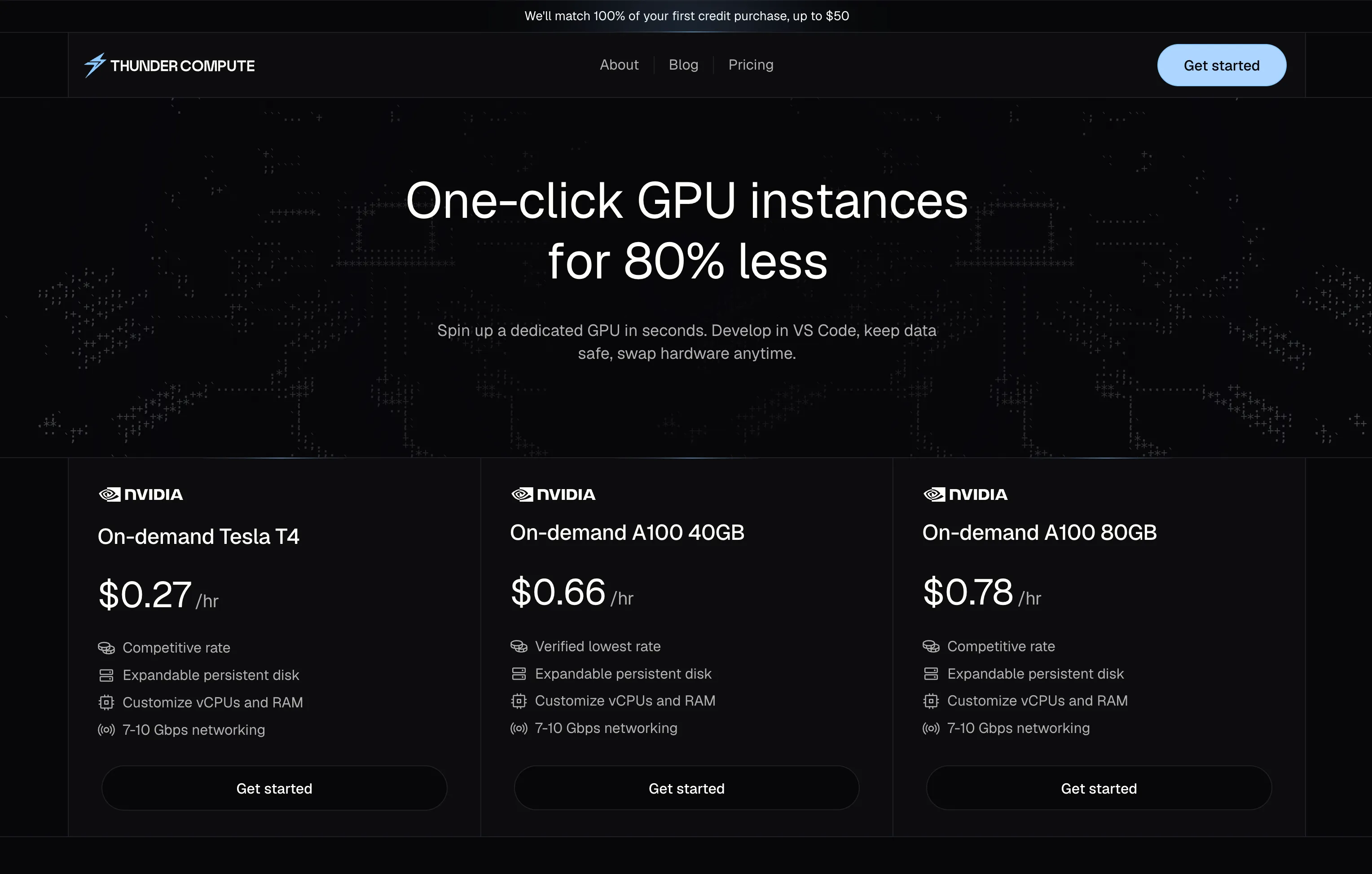
That's where Thunder Compute stands out by offering H100 GPUs at $2.19/hr. These are standard on-demand prices, not promotional rates or spot pricing.
Recent H100 price analysis shows how market dynamics are shifting. Major cloud providers like AWS have cut costs for H100, H200, and A100 instances by up to 45%, according to recent industry reports.
This pricing pressure creates opportunities for developers who were previously priced out of GPU computing. Our H100 pricing comparison shows how large these savings can be.
| GPU Type | Thunder Compute | Typical Competitor | Savings |
|---|---|---|---|
| RTX A6000 | $0.35/hr | $0.39-1.89/hr | 10-81% |
| A100 80GB | $1.09/hr | $1.39-5.07/hr | 22-79% |
| H100 80GB | $2.19/hr | $2.01-11.06/hr | Up to 80% |
A100 vs H100 Cost Analysis
The H100 offers up to 4x the performance of the A100 in specific workloads, particularly those that can use its higher bandwidth memory and improved performance from NVIDIA's Hopper architecture. But performance per dollar tells a different story.
For most fine-tuning tasks, model inference, and development work, A100s provide the optimal balance of power and cost. The H100 GPU price guide breaks down the hidden costs that can make H100 deployments expensive beyond the hourly rate.
Thunder Compute makes it easy to swap GPUs for your projects, which means you can start small and scale in a matter of minutes. We created a GPU selection framework to guide you through this choice.
The cost-performance analysis becomes even more compelling when you factor in development time. Our detailed performance comparison shows how professional-grade GPUs with larger VRAM pools allow workflows that just aren't possible on consumer-level hardware.
Relevant GPUs in 2026
Different GPUs in the cloud market are still relevant depending on the application. Nvidia just announced that Vera Rubin GPUs will increase production and should hit the market in late 2026. But almost the entire supply will get funneled into hyperscalers and will be reserved for large corporations.
For some time to come, architectures like Blackwell and Ada Lovelace will be the newest accessible hardware. And even older ones like Hopper and Ampere are still highly relevant, especially for AI training.
The table below compares today’s most common cloud GPUs based on memory, pricing, and real-world availability. Giving you a quick snapshot of the GPU landscape.
| GPU Name | Architecture | VRAM | Cost Range ($/hr) | Status in 2026 | Pricing |
|---|---|---|---|---|---|
| B200 | Blackwell | 192GB | $3.50–$27.04 | Extremely limited. Pricing inflated due to supply constraints. | B200 Details |
| RTX PRO 6000 | Blackwell | 96GB | $1.11–$4.50 | New workstation-class. Limited cloud adoption. | RTX PRO 6000 |
| H200 | Hopper | 141GB | $2.50–$6.00 | Preferred for memory-bound AI. Premium pricing. | H200 Details |
| H100 | Hopper | 80GB | $2.01–$14.00 | Widely available. Still dominant for AI training. | H100 Details |
| AMD MI300X | CDNA 3 | 192GB | $1.44–$5.20 | Strong H100 competitor. Massive VRAM eliminates multi-GPU sharding for large models. | MI300X Details |
| RTX 6000 Ada | Ada Lovelace | 48GB | $0.61–$0.99 | More powerful GPUs are available for the same price. | 6000 Ada |
| L40 | Ada Lovelace | 48GB | $0.48–$2.20 | Optimized for inference and rendering. | L40 Details |
| A100 | Ampere | 80GB | $1.09–$4.20 | Widely used. Great price-performance ratio. | A100 Details |
| A40 | Ampere | 48GB | $0.60–$1.80 | Declining usage. Viable for inference. | A40 Details |
| RTX A6000 | Ampere | 48GB | $0.35–$1.50 | Popular budget option; high availability. | A6000 Details |
| RTX A5000 | Ampere | 24GB | $0.19–$0.50 | Highly available **budget choice** for light training or early development. | A5000 Details |
| T4 | Turing | 16GB | $0.52–$0.63 | Legacy but available. Lightweight inference. | T4 Details |
| V100 | Volta | 16–32GB | $0.14–$3.36 | Phasing out. Older infrastructure and budget environments. | V100 Details |
GPU Availability and Supply Chain Updates
Supply chain dynamics improved dramatically throughout 2025. Google Cloud made their latest A4 B200 and A4X GB200 instances generally available, competing directly with AWS, Azure, and Oracle Cloud offerings that provide 400Gbit/s per GPU connectivity.
This increased competition among hyperscalers is creating better availability for specialized providers like us. The GPU cloud rating system shows how different approaches to GPU orchestration affect real-world availability and performance.
Our orchestration technology allows near 100% utilization of GPU resources, so we can offer consistent availability even during peak demand periods. This is a major advantage over marketplace-style providers and their sometimes unpredictable availability.
The key insight is that software-driven orchestration optimizes GPU utilization rates, meaning better availability and lower costs for end users.
RAM Supply Constraints
While GPU chip production has stabilized, the market is currently facing a significant structural memory supply shortage that began in late 2024.
This shortage is primarily driven by a massive reallocation of wafer capacity. Tier-1 manufacturers (Samsung, SK Hynix, and Micron) are aggressively shifting production from standard DDR5 DRAM and NAND flash toward High Bandwidth Memory (HBM3e/HBM4). Their goal is to fulfill massive contracts for AI data center infrastructure.
Recent industry data indicates that large-scale AI initiatives are projected to consume up to 40% of global DRAM output. This competition for wafer starts has led to a 200–400% price escalation in the semiconductor memory market.
Major hardware OEMs like Dell and HP have reported that memory now accounts for up to 35% of total build materials, a sharp increase from the historical average of 15-18%.
Our proprietary orchestration technology is engineered to mitigate these supply chain volatility risks. By maintaining near 100% resource utilization, we provide consistent availability even as hardware costs fluctuate.
Major Cloud Provider Competition
The competitive market has three distinct tiers:
- Enterprise: AWS, Microsoft, and Google dominate with full-service offerings but premium pricing.
- Specialized: providers like CoreWeave focus on high-performance cloud computing optimized for large-scale training and inference, often with the newest NVIDIA hardware.
- Cost-focused: providers in this tier combine accessibility with competitive pricing. This is where Thunder Compute operates, offering the reliability and ease of use you'd expect from major cloud providers with a simpler developer experience and lower prices.
The GPU market evaluation report shows how different providers are positioning themselves. Major clouds compete on enterprise features and global reach. Specialized providers compete on performance and cutting-edge hardware access.
We strive to remove friction and deliver exceptional value. Our VS Code integration, one-click deployment, and persistent storage come standard, not as premium add-ons. When you compare total cost of ownership, including setup time and day-to-day overhead, Thunder Compute often delivers better value even before considering our price.
The Lambda alternatives analysis shows how different providers serve different use cases. Our sweet spot is developers and teams who want professional-grade GPU access without enterprise complexity or pricing.
Specialized GPU Providers Changes - June 2026
Several cloud providers dropped GPUs between May and June, phasing out older node architectures or shifting next-generation chips away from standard on-demand rental:
- Vast.ai recorded price increases for premium hardware:
- H100 rate went from $1.93 to $2.01
- H200 rate went from $2.29 to $3.71
- Blackwell B200 tier went from $3.81 to $5.64 Several less popular GPUs were also dropped from popular providers.
- The NVIDIA L40S saw widespread removals across multiple cloud providers including Crusoe Cloud.
- Vast.ai officially dropped support for several aging architectures, removing the V100 16GB, the A40, and the RTX A6000 from its catalog.
- TensorDock also dropped the A40.
All of this information comes from our own monthly analysis that includes 25 different providers.
AI Startup GPU Requirements Evolution
AI startups have unique requirements. They usually need production-grade infrastructure for rapid iteration and deployment, but are running lean and can't commit to long-term contracts.
Training complex models like LLMs from scratch requires thousands of GPUs, but most startups are fine-tuning existing models or building specialized applications.
This is where Thunder Compute's flexible scaling model shines. You can start with a single A100 for development and experimentation, then move to an H100 or scale out to more GPUs when you're ready for larger training runs. No long-term commitments, no complex configurations.
The GPU machine learning comparison between on-premises and cloud approaches shows why startups increasingly choose cloud-first strategies. The capital requirements and complexity of managing your own GPU infrastructure don't make sense for most early-stage companies.
Our startup-focused GPU cloud guide breaks down the specific considerations for Series A and Series B companies. The ability to iterate quickly, scale resources on demand, and maintain cost predictability often matters more than having access to the absolute latest hardware.
GPU provider comparisons show how different companies approach GPU infrastructure decisions. The common thread among successful AI startups is choosing providers that allow rapid experimentation without extra overhead.
Regional Market Differences and Global Expansion
GPU rental prices vary widely by region, creating opportunities for cost optimization. A 2025 regional pricing analysis found U.S. East Coast deployments averaging $5.76 per unit per day, while West Coast deployments ran $6.60 per unit per day. These regional price variations can add up to substantial differences for long-running workloads.
North America concentrates most of the world's data centers, but Asia Pacific is projected to be the fastest-growing region. This expansion is creating new opportunities for providers who can deliver consistent experiences across regions.
 * AI Index Report: 1.3 Data Centers
* AI Index Report: 1.3 Data Centers
Thunder Compute's global accessibility provides consistent performance, developer experience, and pricing across regions.
For developers and startups, the key is finding providers who can deliver consistent experiences without requiring you to become experts in global infrastructure management.
Technology Infrastructure Improvements
Recent advances in GPU networking, cooling, and data center performance are allowing better price-performance ratios across the industry. NVIDIA's vision for "AI factories" includes large-scale data centers with advanced power and cooling systems, such as the Lancium Clean Campus in Texas scaling from 200 MW to 1.2 GW by 2026, hosting up to 50,000 GPUs per building.
These infrastructure improvements create opportunities for better GPU use and improved cost economics. The data center market trends show how power improvements, cooling advances, and networking progress are reducing costs.
Thunder Compute's orchestration technology allows features like swapping GPU types, persistent storage, and near-instant scaling. These features come from software improvements rather than hardware scale, which allows us to pass savings on to users.
2026 Market Outlook
Looking back at late 2025 and early 2026, several trends should come together to create a more mature and competitive GPU rental market. Prices are expected to stabilize with potential discounts from new GPU releases, while analysts predict relatively stable H100 prices with only minor adjustments despite ongoing enterprise demand.
The GPU-as-a-service market analysis suggests that competition will increasingly focus on developer experience, reliability, and specialized features rather than price competition alone.
This plays to Thunder Compute's strengths. We built a service around developer experience from day one, with VS Code integration, one-click deployment, and persistent storage as standard features. As the market matures, these differentiators become more important than pure price competition.
The supply chain improvements and increased competition among hardware providers should continue to benefit end users through better availability and more predictable pricing. There are still wild price swings and availability constraints like in 2023-2024, but eventually they should give way to a more stable market.
Impact of News from NVIDIA GTC Taipei 2026
NVIDIA’s latest announcements at GTC Taipei and Computex 2026 will directly impact infrastructure procurement and rental market trends over the coming quarters:
- Vera Rubin Slashes Token Costs: NVIDIA revealed that next-generation GPUs are already in full production, with shipments expected to begin in Q3 2026. The rack-scale system, the Vera Rubin NVL72 (36 Vera CPUs coupled with 72 Rubin GPUs via next-gen NVLink) slashes the cost per token by a factor of ten. The demand for this hardware should stabilize supply of current-generation Hopper and Ampere clusters.
- Supply Chain Stabilization: To prevent the severe hardware bottlenecks that plagued the market since 2023, NVIDIA confirmed multi-year technology partnerships with memory giants (SK Hynix, Samsung, and Micron). This diversified and resilient supply chain should secure production lines for advanced HBM4 and HBM5 memory.
Until new hardware hits the market and we start seeing how it plays out, this is mostly speculation. But it is certain that NVIDIA sees lost profit in the current supply shortage, and they will want to rectify that.
Final thoughts on AI GPU rental market shifts
The AI GPU rental market has changed dramatically, with prices dropping and availability improving across the board. Whether you're fine-tuning models or running experiments, you can now rent AI GPUs at prices that make sense for your projects.
FAQ
What's the main difference between A100 and H100 GPUs for AI development?
H100s offer up to 4x the performance of A100s in specific workloads, particularly those using higher bandwidth memory and NVIDIA's Hopper architecture. However, A100s provide better cost-performance for most fine-tuning tasks, model inference, and development work, making them a great choice for many AI development tasks.
How much can I save by switching from major cloud providers to specialized GPU rental services?
Savings vary by GPU and provider, but Thunder Compute is often cheaper than fixed-price and hyperscaler options. For example, A100 80GB instances cost $1.09/hr compared with roughly $1.39-$5.07/hr across tracked competitors, and H100 80GB instances cost $2.19/hr compared with roughly $2.89-$11.06/hr across several non-marketplace providers.
What should I consider when choosing between different GPU rental providers?
Focus on three key factors: pricing transparency, reliable availability, and developer experience features. Look for providers offering consistent on-demand pricing (avoid spot-only rates), reliable availability during peak demand, and built-in conveniences like VS Code integration, persistent storage, and one-click deployment.